
ビジネスを立ち上げる時には、何よりスピード感が大事で、すぐに開発に取り書かれる、経験があってイメージしやすいアーキテクチャで開発をスタートするというのはよくある話です。
弊社のCircuitXの一部のサービスもAWS ELB + EC2、そのEC2でrubyが稼働しているというよくある構成で、とりあえず開発を始めたまま現在に至るまで稼働しておりましたが、レガシーシステムから脱却するため、AWS ECS fargate + Golangの組み合わせでリプレイス行いました。
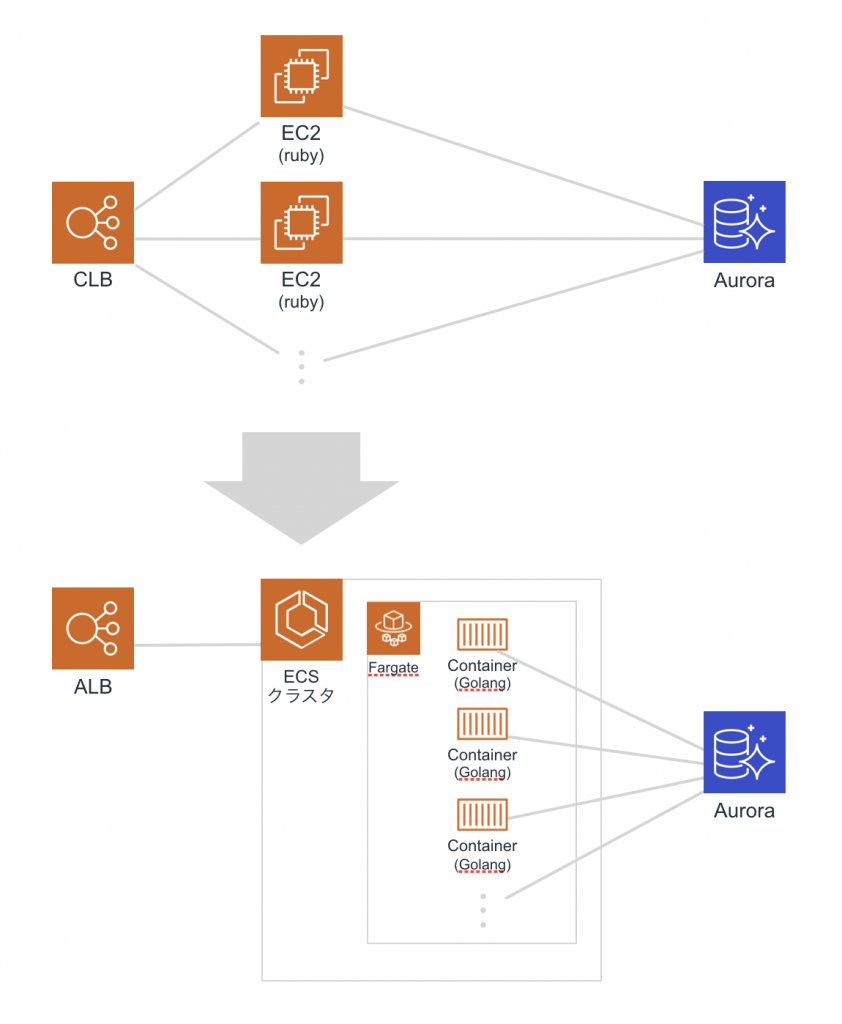
今回はそのリプレイスについて、まずは概要をご紹介しようと思います。
※ECS fargateやGolangについての詳細は別の記事で書きたいと思います。
抱えていた課題
今回リプレイスするにあたって解決したい課題は、ざっくり2つありました。
アプリケーションの実行パフォーマンス
1つ目として、アプリケーションパフォーマンスの改善があります。事業の成長と共にトラフィックも増大してきました。嬉しい悲鳴ですが、特にこの1〜2年で、CircuitXを開発した当初では想像もしなかったトラフィック量になりました。それに伴い、コスト面を考慮した柔軟なキャパシティコントロールや突発的なトラフィックに対応できるスケールアウトを実現したいというのが解決したい課題の1つ目です。
開発効率
2つ目としては、開発効率の改善です。サービスを運用していくうちにビジネス要件の変更や追加が進み、その都度、要件を満たす開発が行われていきます。最初のうちは、開発はスムーズに進みますが、そういったことを繰り返していくうちに、変更を行うのが難しくなっていきます。
今回リプレイスを行ったサービスは、rubyのSinatraで作られたものでしたが、既存コードの複雑化し、コードを変更する際に手間がかかるようになってきました。元々は開発効率を重視して使っていたフレームワークだったのですが、徐々に効率が下がっていくという結果になってしまいました。
もちろんそういった技術的負債を抱え込まないように注意して実装していくことも可能だと思いますが、頭で理解していても実際にチームで実践していくのはなかなか難しいものです。この問題のことを書籍『エンジニアリング組織論への招待』では、
システムを連続的にアップデートしながら作っていくときには、中身を知らない人から見ると予想外のタイミングで、予想外の形で開発が進まなくなるという現象
エンジニアリング組織論への招待
と表現され、ジェンガのようなものと例えられていますが、まさしくジェンガのような状況だと思いました。

このようにアプリケーションの実行パフォーマンスも開発効率も悪いという2重苦を抱えてしまったという背景から、リプレイスを決断しました。
ECS fargate
フクロウラボのシステムのインフラは、AWSをメインに使用していますが、既存のシステムは、ELBの下にEC2郡がぶら下がっている構成でした。この構成はよく見かける構成ではありますが、いくつかデメリットを感じていました。
まず、EC2では、OSやミドルウェアの管理から自分たちで行わないとならない点です。発生頻度が少なかったことから、このあたりの対応コストを軽く見てしまっていたのですが、インスタンスの数が増えていくと、頻度も作業工数も上がっていきます。例えば、何かしらのミドルウェアをアップデートした場合、staging環境で動作検証をした上でAMIの更新を行い、プロダクション用のインスタンスも全て更新していく運用になりますが、よくよく考えると面倒ですよね。
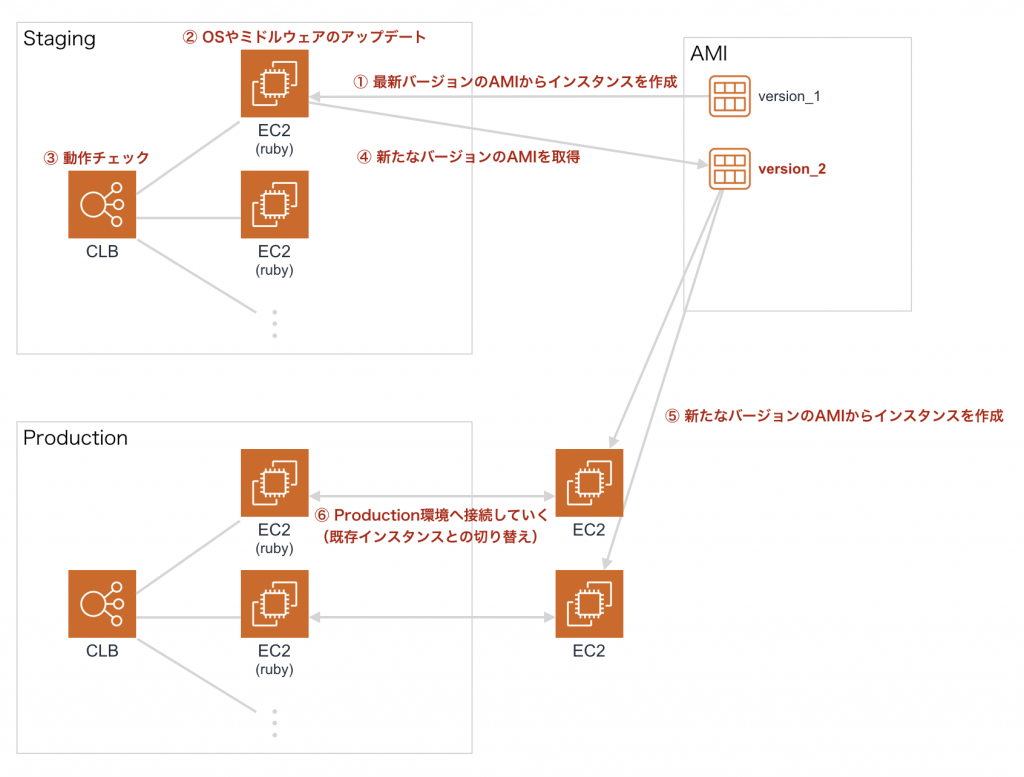
次に、デプロイの複雑化も進んでいくというのがあります。先の記事にて、CI/CDの自動化の紹介をしましたが、自動化してもデプロイ完了までの時間はそれなりに掛かかるようになってしまいました。
ECS fargateのコンテナ起動は、EC2のインスタンス起動に比べると高速です。また、OSやDocker Engine、ecs-agentなどのバージョンアップやセキュリティパッチの適用を行う必要がなくなります。管理が必要なものといえば、ランタイムの管理くらいになるというのも魅力的でした。
Golang
webアプリケーションとしての相性を考えると、開発言語の選択は、Java、Perl、Scala、Golang、C#、Python、PHP、Ruby、Node.jsあたりなると思いますが、その中でGolangを選択した理由はいくつかあります。
まず、実行パフォーマンスを考えると、インタプリタは卒業したいというのがありました。今回リプレイスしたサービスはシンプルな処理が多く、フルスタックなフレームワークなども必要ありませんでした。
コンパイル言語にしぼるとJava、Perl、Scala、Golang、C#などとなりますが、フクロウラボ社内で興味がある言語ランキング1位だったのがGolangでした。Golangのメリットととしては、実行パフォーマンスの良さ、コンパイルが高速、メモリ管理がセキュア、goroutineによる並行処理などが考えられます。
逆にGolangのデメリットとして、継承が無いというところを指摘されることがあります。Golangの場合、埋め込みとインターフェイスを使用することでオブジェクト指向的な振る舞いを実装していくことになりますが、その際に継承という選択肢を端から排除し、コンポジションでの実装を強制するというのがGolangの特徴とも言えます。この辺りの見解は人によって異なり、割と”エモい”話になるかもしれないので、ここでは深くは触れません^^;
また、巨大なモノリシックRailsアプリケーションへの逆風というここ数年のトレンドもあり、Golangを採用している企業となることで、採用効率も多少でも改善できないかと淡い期待を持っています。
以上の理由から、言語はGolangを採択しました。
リプレイス後の改善されたところ
リプレイス前に抱えていた課題は、おおよそ狙い通り改善できたと思います。
デプロイフロー
大まかなデプロイフローは下記になります。
・dockerイメージとしてビルド
・AWS ECRへアップロード
・ECSクラスタの更新
手動でデプロイする場合でも、ローカル環境にてコマンドを数回実行するだけで、デプロイできるようになりました。ECSクラスタのコンテナ郡のデプロイにおいてもecs-cliのコマンド1つで、CodeDeployによって制御されるBlue/Greenデプロイモデルを利用することができます。
実際にはgithubのmasterブランチへのマージのタイミングでCircleCIにてテストの実行と一緒にデプロイまで行うように自動化しましたので、下記の図のような仕組みになりました。
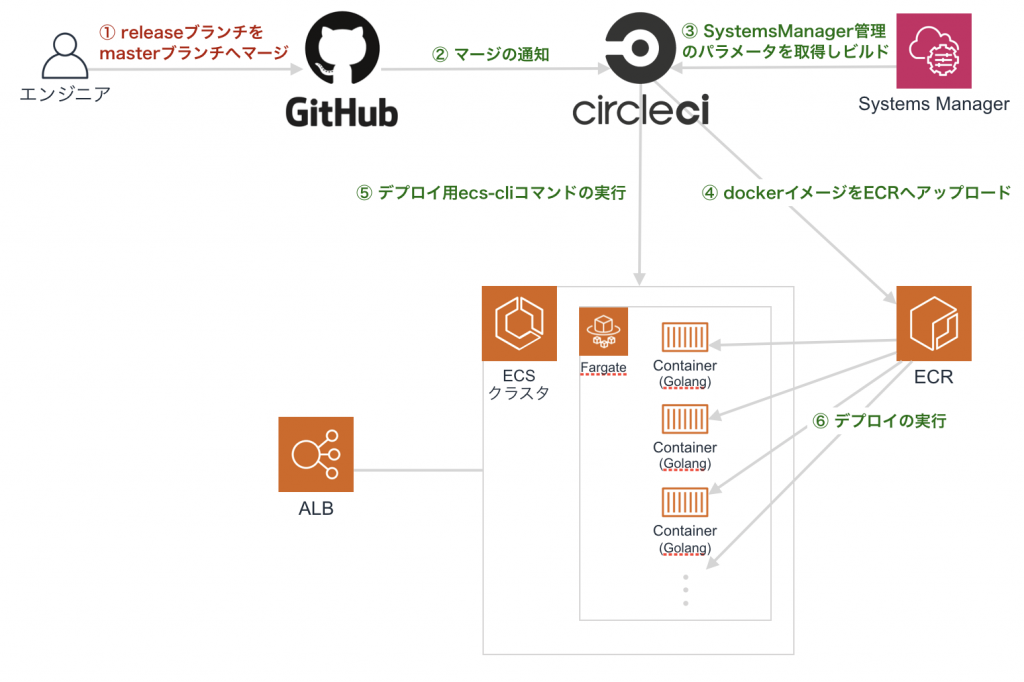
「①releaseブランチをmasterブランチへマージ」をトリガーに、②移行の緑色のフローは全て自動化した部分です。
ステートレス
元々インスタンス固有の情報が少ないアプリケーションでしたが、インスタンス毎に保存していたアプリケーションログもCloudWatch Logsで管理できるため、より純粋にステートレスなリソースとして扱えるようになりました。
実行(≒コスト)パフォーマンス
EC2 + rubyとECS fargate + Golangの比較というのと、詳細なデータがない、かつ、同条件での比較ではないので参考にならないと思いますが、従来に比べるとインフラ料金のコストは3分の1程度にはなりました。コンピューティングリソースを単純に時間単価で比べるとEC2 の方が安価であることと、リプレイス後の新システムでは、旧システムより多少冗長な構成にしていることを考慮すると、GolangのCPUやメモリリソースの効率が優秀だと個人的には感じています。
反省点と残された課題
見積もり
リプレイスを実装していくチーム体制ですが、専属メンバー2名で進めました。最初の見積もりでは、3スプリント(1スプリント2週間)くらいでの完了を想定していましたが、結果的には倍の6スプリントくらいかかってしまいました。初回のリリースはおおよそ想定通りの見積もりでできたものの、プロダクション環境へのデプロイ後に想定外のバグが見つかり、一旦、旧システムへロールバックしてデバッグ後に再デプロイという事象が何回か発生してしまい、結果として約3ヶ月かかってしまいました。ここは反省点で大いに改善の余地がありそうです。
慣れない言語でのクリーンアーキテクチャ
メモリ管理の不手際により、特定の条件下で直前のリクエスト処理で使われた値をそのまま使用してしまうといったようなバグやDBコネクションの取り回しに不備がありコネクションプーリングができていない状態だったなど、設計レベルで改修する部分がありました。一朝一夕でどうにかなるものでもありませんので、失敗や経験からクリーンアーキテクチャを意識した実装の練度を上げていくよう精進するしかありません。
残された課題
JMeterを使って、負荷テストを行い、想定していた量のトラフィックの処理は問題なく捌けることは担保できました。ただ、ECSクラスタのリソース管理よりも、DB(Auroraクラスタ)のリソース管理がボトルネックになることが見えてきました。この課題に対してはAuroraクラスタに対してきちんとスケーリングポリシーの作成し想定通りのAuto Scalingの運用ができるように整えるという別の課題として対応していきたいと思います。
また、エラーが発生した場合は、Slackへの通知を行うようにしています。よくあるパターンとして、何かしらのトラブルやキャパシティを超えた状態でさらにリクエストが重なると、立て続けにエラー処理が発生するようになると思います。たとえ瞬間的なエラーハンドリングの通知によっても、SlackのAPIの上限を超えてしまいということが起こりえますので、こちらもQueueを間に挟むなど、今後の解決策を考えていきたいと思います。
/assets/images/4387760/original/efe3ba5d-4c9f-4873-b521-1738e80ecedc?1581036553)


コメントを残す